
The three frameworks Storm, Spark, and Hadoop have their own advantages and each framework has its own application scenarios. Therefore, these three different frameworks should be chosen in different application scenarios.
Storm Framework
The Storm Framework is the best-streaming computing framework. The storm is written by Java and Clojure. The advantage of Storm is full memory computing, so it stands as a distributed real-time computing system.
Storm Application Scenarios
- Stream data processing – Storm can be used to process the incoming and outgoing messages, and then write the results to a certain storage.
- Distributed RPC – Because Storm’s processing components are distributed and have very low processing latency, they can be used as a general purpose distributed RPC framework.
Spark Framework
Spark is an open source cluster computing system based on memory computing, which aims to analyze data more quickly. Spark is similar to Hadoop MapReduce’s general parallel computing framework.
Spark Application Scenarios
- Application of multiple data sets for multiple operations – Spark is a memory-based iterative computing framework for applications that require multiple operations on specific data sets. The more times you need to repeat the operation, the larger the amount of data you need to read, the greater the benefit, and the smaller the amount of data, but the greater the computationally intensive, the less beneficial.
- Application of coarse-grained update status – Due to the nature of RDD, Spark does not apply to applications that use asynchronous fine-grained update states, such as Web service storage or incremental Web crawlers and indexes. It is not suitable for the application model of incremental modification. In general, Spark’s application is more extensive and more general.
Hadoop Framework
Hadoop implements the idea of MapReduce, which computes data to process a large amount of offline data. The data processed by Hadoop must be stored in HDFS or HBase like database, so Hadoop is implemented by mobile computing to improve the efficiency of these data storage machines.
Hadoop Application Scenarios
- Data analysis, such as massive log analysis, commodity recommendation, user behavior analysis
- Offline calculation, (heterogeneous calculation + distributed calculation) astronomical calculation
- Large-scale Web information search
- Data-intensive parallel computing
- Massive data storage
Key Differences In Simple Terms
- Hadoop is suitable for bulk data offline processing is suitable for very low real-time requirements of the scenario.
- Storm Suitable for real-time streaming data processing, excellent in real-time performance.
- Spark is a memory distributed computing framework and similar to Hadoop’s MapReduce batch framework and Storm’s stream processing framework. But Spark has done a very good job in batch processing aspect, performance is better than MapReduce, but stream processing is still weaker than Storm, and the product is still improving.
Hadoop Application Business Analysis
Big data is a collection of large data sets that cannot be processed using traditional computing techniques. It is not a single technology or tool, but rather involves many areas of business and technology.
Currently, the three major distributed computing systems are Hadoop, Spark, and Storm.
One of Hadoop’s current big data management standards is used in many current commercial applications. Structured, semi-structured, and even unstructured data sets can be easily integrated.
Spark uses in-memory computing. Starting from multiple iterations of batch processing, data is loaded into memory for repeated queries. In addition, various computing paradigms such as data warehouse, stream processing, and graphics computing are combined. Spark is built on HDFS and works well with Hadoop. Its RDD is a big feature.
Storm is a distributed real-time computing system for high-speed, large data streams. Added reliable real-time data processing capabilities to Hadoop.
Apache Hadoop is an open source framework written in Java that allows distribution of large data sets in a cluster, using a simple programming model. Hadoop framework application engineering provides an environment for distributed storage and computing across computer clusters. Hadoop is designed to scale from a single server to thousands of machines, each providing local computing, and storage.
The Basic Principles of Hadoop
Hadoop distributed processing framework core design:
- HDFS – Hadoop Distributed File System
- MapReduce is a computing model and software architecture.
HDFS
HDFS (Hadoop File System) is a distributed file storage system of Hadoop. It decomposes large files into multiple blocks, each holding multiple copies. Provides a fault-tolerant mechanism that automatically recovers when a copy is lost or down. By default, each block holds 3 copies, and 64M is 1 block. Map the block to memory by key-value.

MapReduce
MapReduce is a programming model that encapsulates details such as parallel computing, fault tolerance, data distribution, and load balancing. The MapReduce implementation begins with mapping the map and operations to each document in the collection, grouping them according to the generated keys, and placing the resulting list of key values into the corresponding keys.
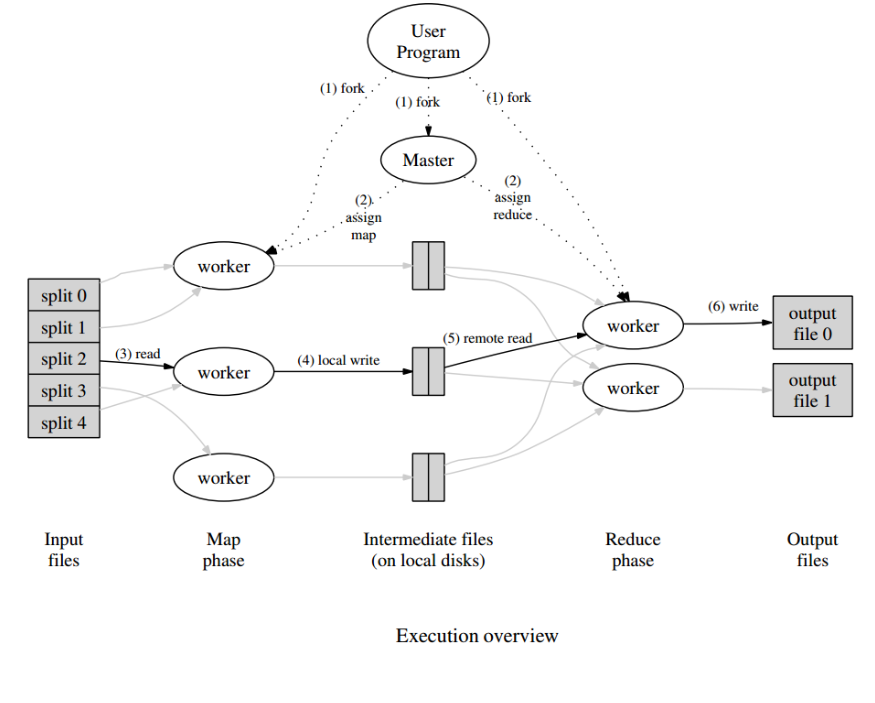
The MapReduce program is implemented in three phases, the mapping phase, the shuffle phase, and the reduction phase.
Mapping phase
Reduction phase
HIVE
Hive is a data warehouse tool based on Hadoop. It can map structured data files into a database table and provide complete SQL query function. It can convert SQL statements into MapReduce tasks. This set of SQL is referred to as HQL. Make it easy for users unfamiliar with mapreduce to query, summarize, and analyze data using SQL language. Mapreduce developers can use the mapper and reducer they write to support Hive for more complex data analysis.

As you can see from the above figure, hadoop and mapreduce are the foundation of the hive architecture. The Hive architecture includes the following components: CLI (command line interface), JDBC/ODBC, Thrift Server, WEB GUI, metastore, and Driver (Compiler, Optimizer, and Executor).
The author Kiran Gutha has an experience of more than 6 years of corporate experience in various technology platforms such as Big Data, AWS, Data Science, Artificial Intelligence, Machine Learning, Blockchain, Python, SQL, JAVA, Oracle, Digital Marketing etc. He is a technology nerd and loves contributing to various open platforms through blogging. He is currently in association with a leading professional training provider, Mindmajix Technologies INC. and strives to provide knowledge to aspirants and professionals through personal blogs, research, and innovative ideas. You can reach him at: Linkedin or Email.